I. Introduction.
core trick - CF - based on similarity
Two CFs -
1. User CF
2. Item CF
Applications - amazon commodities/ netflix movies.
For now, let's talk about movie.
User CF - based on user similarity
Item CF - based on item similarity

Let's use item CF dude,
item have less unique quantities.
items' properties seldom change.
you like marval ant's man, i present you the iron man, sounds convincing.
II. Procedures
1. co-occurrence matrix
2. rating matrix
3. matrix computation to get recommendation result.
Ok, how to tell the similarity between different movies?
I suggest using machine learning e.g. logistic regression -
and that requires feature -
1. users
watching history
rating history
favorite list
2.
movies category
movies
Let's brainstorm -
e.g. if one user rated two movies, these two are related.
calc

Rated Matrix

How about ratings?
Rating Matrix

Normalization

Conditional probability matrix not symmetrical
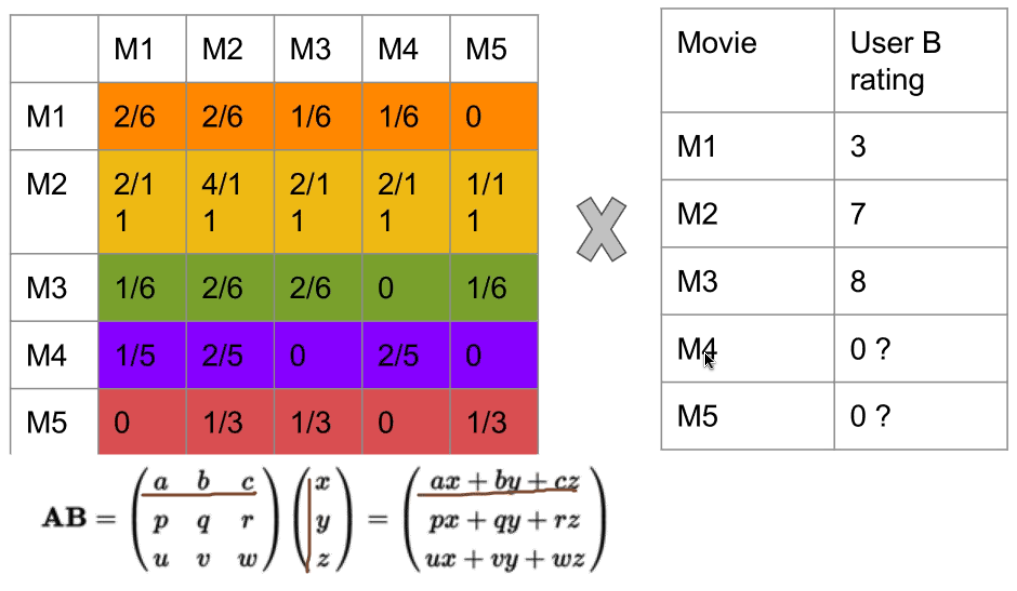
没看过, rating 可以给一个平均分
Q&A
Q: 为什么没看过rating就是0?
A: 这个地方可以改进, 没看过, rating 可以给一个平均分
Q: 例如说来了个新用户小白,他的列全是零
Q: 用户没看过的电影rating给0分会不会影响第一个相似性矩阵的真实性? A: 会的。 一般一个更好的做法是 给没看过的电影系统平均分
Logistic regression -> Deep learning.
No comments:
Post a Comment